What is a Data Engineer?
In the modern tech ecosystem, a data engineer is the architect and builder of robust, scalable, data-driven systems. They bridge the critical gap between raw, messy data and actionable business intelligence, ensuring that information can be easily accessed and utilized across an organization.
We need data engineers because enterprise data is rarely ready to use out of the box. It is often scattered across multiple internal and external sources, highly unstructured, and generated at a massive, overwhelming scale. Data engineers are responsible for designing the infrastructure to collect, process, clean, and store this data, ultimately transforming it into a reliable format that data scientists and analysts can use to build machine learning models or insightful dashboards.
Key Responsibilities Include:
- Architecture Design: Designing, building, and continuously monitoring the architecture of scalable data platforms and pipelines.
- Data Ingestion: Consolidating data from disparate sources (such as APIs, transactional databases, and flat files) into a centralized repository.
- Implementing Data Governance: Ensuring that the organization’s data is trustworthy and secure. This involves managing data quality, enforcing security and privacy policies, and setting up strict data access management controls.
- Data Lifecycle Management: Overseeing the entire journey of data, which includes:
- Data Collection & Processing: Extracting and transforming raw data.
- Data Storage: Choosing the right storage layer (e.g., relational databases, NoSQL, or distributed file systems).
- Data Usage & Analysis: Providing optimized views and tables for downstream consumers.
- Data Archival & Deletion: Managing data retention policies to comply with legal regulations and reduce storage costs.
.webp)
The Data Pipeline
A data pipeline is an automated set of processes that extracts data from various sources, transforms it into a clean and usable state, and loads it into a destination for storage or analysis.
Core Pipeline Components:
- Sources: Where the data originates (e.g., CRM systems, web logs, IoT sensors).
- Staging/Landing Area: A temporary storage zone where raw data is held before it undergoes heavy transformation.
- Data Warehouse: The highly structured, central repository optimized for analytics.
- Data Mart: A specialized subset of the warehouse designed for specific business units.
To move data through these components, engineers rely on powerful ETL tools like Talend or Apache NiFi, and processing frameworks like Python and Apache Spark. There are two primary paradigms for this data movement:
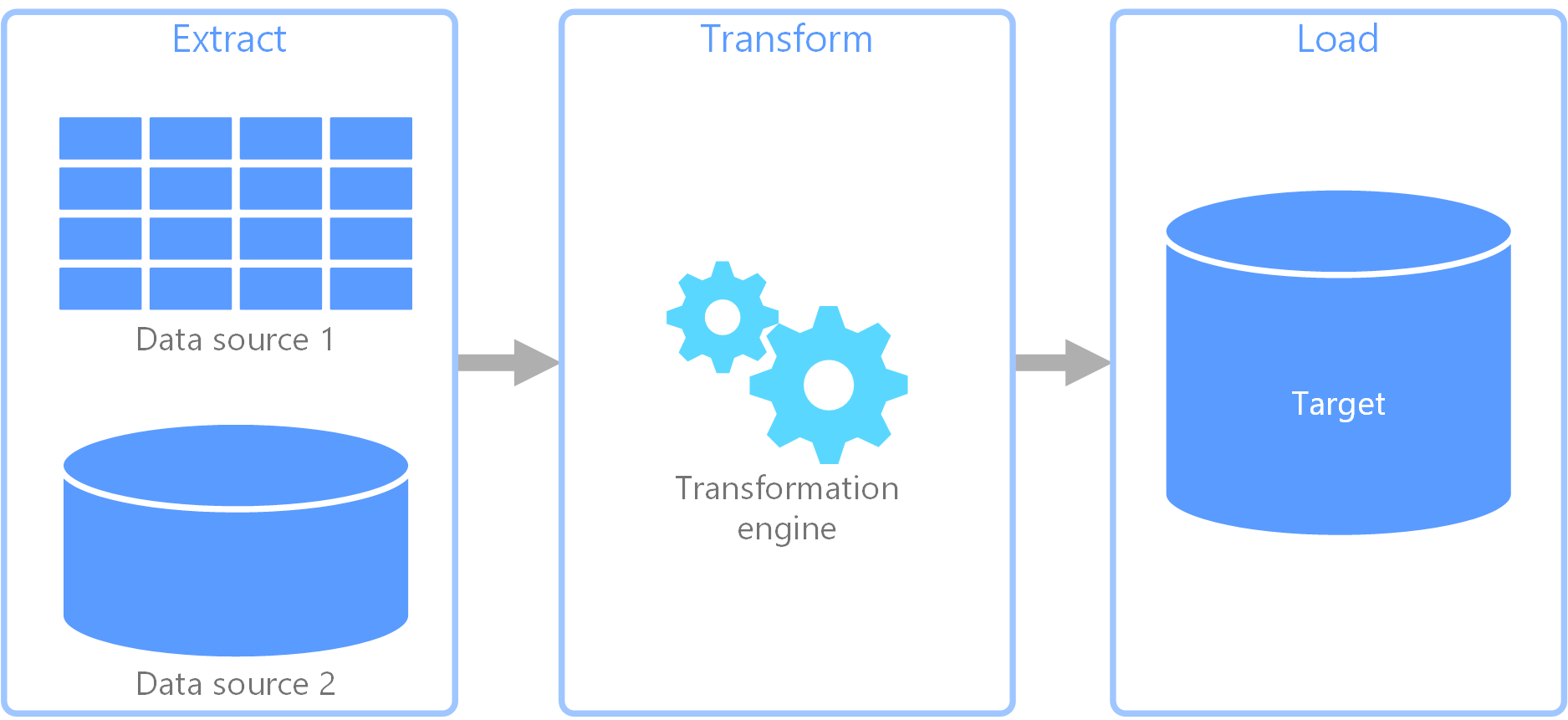
ETL (Extract, Transform, Load)
Historically the standard approach, ETL involves extracting data from a source, transforming it on a separate processing server, and then loading the clean data into the target database.
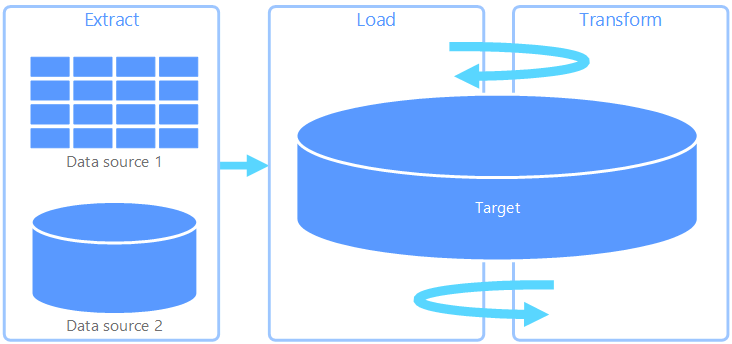
ELT (Extract, Load, Transform)
With the rise of powerful, scalable cloud data warehouses, ELT has become increasingly popular. Here, raw data is loaded directly into the target system, and transformations are performed entirely within the database itself using its own computing power.
- Advantages of ELT:
- Highly flexible data formats, as raw data is stored immediately.
- On-demand transformation allows analysts to transform data only when needed.
- Significantly faster initial loading speeds since there is no intermediate processing bottleneck.
- Disadvantages of ELT:
- Requires highly scalable and often expensive cloud infrastructure.
- Storing raw, sensitive data directly in a centralized repository may pose compliance and security risks.
- Querying unoptimized, raw data can slow down analysis if not managed properly.
Data Ingestion
Data ingestion is the initial and crucial process of extracting and transporting data from one or multiple sources to a target storage destination. The method chosen depends entirely on the business’s latency requirements.
- Batch Processing: Data is collected and processed in large chunks at scheduled intervals (e.g., every night at 2 AM). It is efficient for historical reporting where real-time accuracy is not critical.
- Stream Processing: Data is ingested and processed continuously as it is generated (e.g., fraud detection systems or real-time recommendation engines).
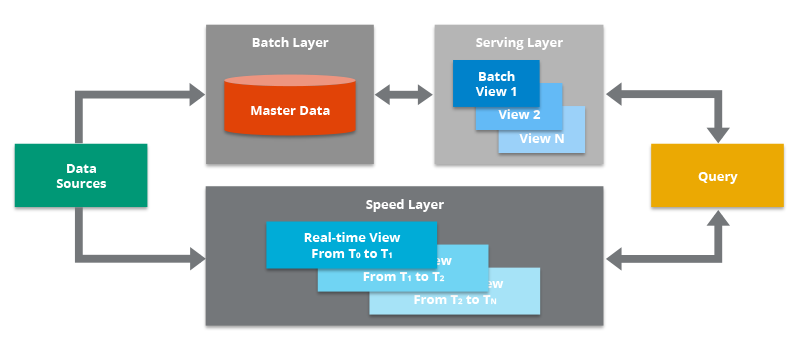
- Lambda Architecture: A hybrid robust approach designed to handle massive quantities of data by utilizing both batch and stream-processing methods. It provides a comprehensive view by combining a historical batch layer with a real-time speed layer.
OLTP vs. OLAP
Understanding how data is written and read is fundamental to designing the right system.
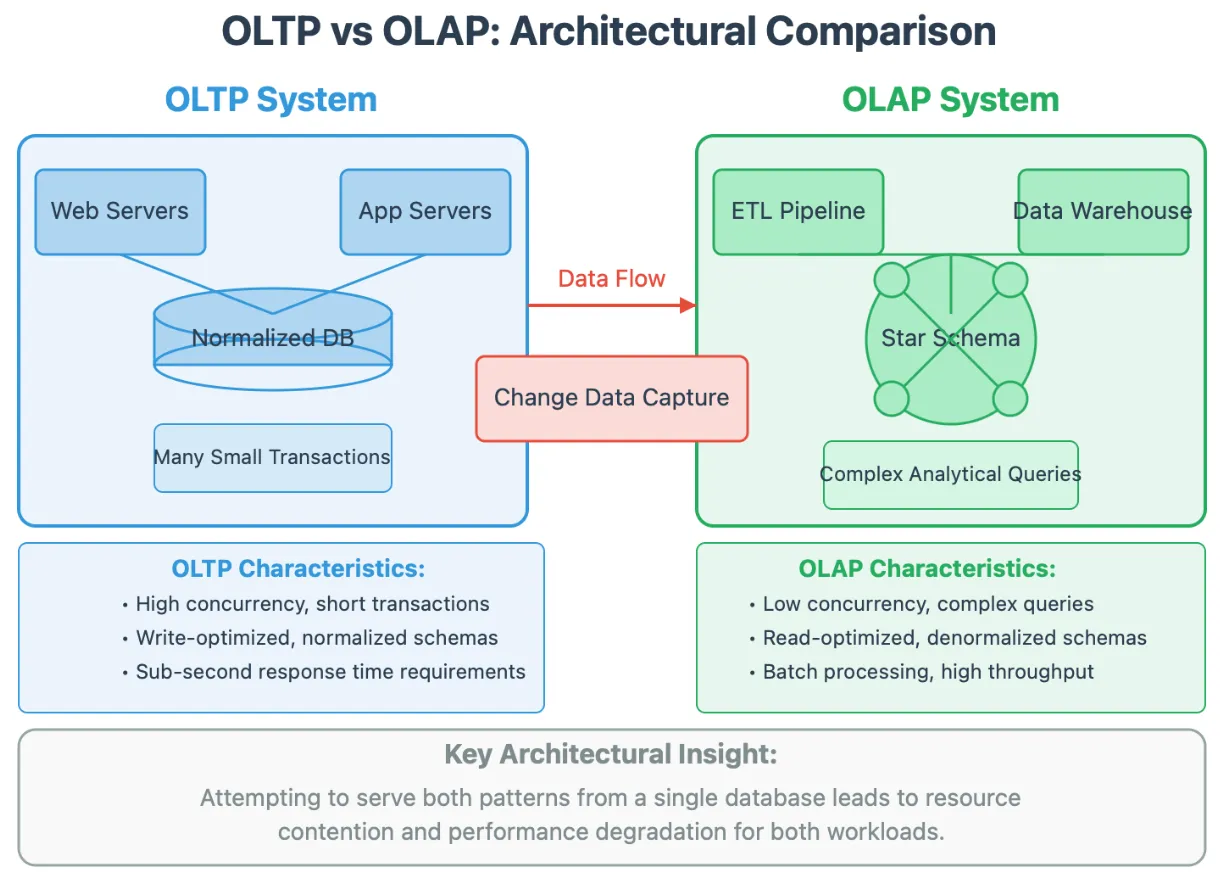
- OLTP (Online Transaction Processing): Optimized for capturing, storing, and processing real-time transactional data. These systems handle a massive volume of short, fast, atomic queries (e.g., simple
INSERTorUPDATEcommands when a customer checks out of an e-commerce store). - OLAP (Online Analytical Processing): Optimized for complex queries, historical data analysis, and business intelligence. Instead of single-row updates, OLAP systems (like Impala or Greenplum) scan massive volumes of data to perform aggregations (e.g., calculating the total sales revenue across all regions for the past five years).
Data Lake, Data Warehouse, & Data Mart
As data ecosystems grow, organizations utilize different storage architectures to serve different needs.
- Data Lake: A highly scalable, cost-effective storage repository that holds vast amounts of raw, unstructured, or semi-structured data (like JSON files, images, or clickstream data) exactly as it was generated. The goal is to store everything at a low cost until it is needed for processing. Engineers often use engines like Apache Hive or Spark to query this raw data directly.
- Data Warehouse: A centralized, highly structured repository where data from various sources is transformed, integrated, and organized. Data here is typically arranged in dimensional models like star or snowflake schemas. It acts as the “single source of truth” and is optimized to support complex business intelligence and analytical queries.
- Data Mart: A specialized, smaller-scale subset of a data warehouse focused entirely on a specific business function or department (such as Sales, Marketing, or HR). By isolating this data, data marts deliver highly curated information tailored for targeted, fast business analysis without requiring users to navigate the entire warehouse.

Relational vs. Non-Relational Databases
Relational Databases (SQL): These databases organize data into strictly structured tables with rows and columns, linked together by primary and foreign keys. They enforce a rigid schema before data can be written and use SQL (Structured Query Language) for all interactions. They are the gold standard for applications requiring high data integrity and complex, ACID-compliant transactions (e.g., banking systems). Common Tools: PostgreSQL, MySQL, MS SQL Server.
Non-Relational Databases (NoSQL): Designed for flexibility and scale, NoSQL databases do not require a fixed schema. They utilize various data models, such as document stores, graph databases, key-value stores, or wide-column stores. This makes them highly horizontally scalable and perfect for managing unstructured, rapidly changing data, or applications serving millions of concurrent users. Common Tools: MongoDB, Cassandra, Redis.
