Data engineer is someone who builds a data-driven system so that data can be easily utilized by a company.
We need data engineers because the data is scattered in many places, still raw, and too big. Data engineers are responsible for collecting, processing, and storing data so that it can be used by data scientists and analysts.
The tasks of data engineer:
Designing and monitoring the architecture of Data Platform and Pipeline
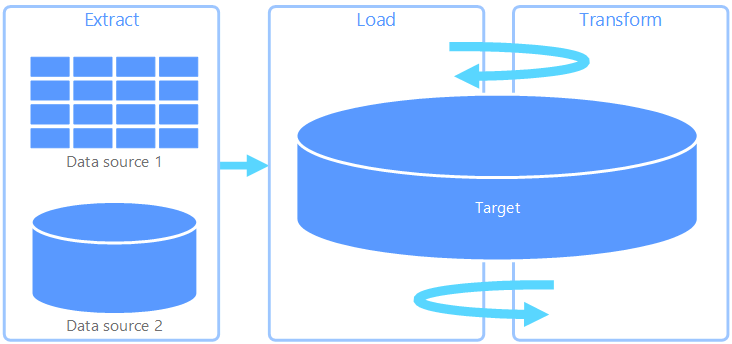
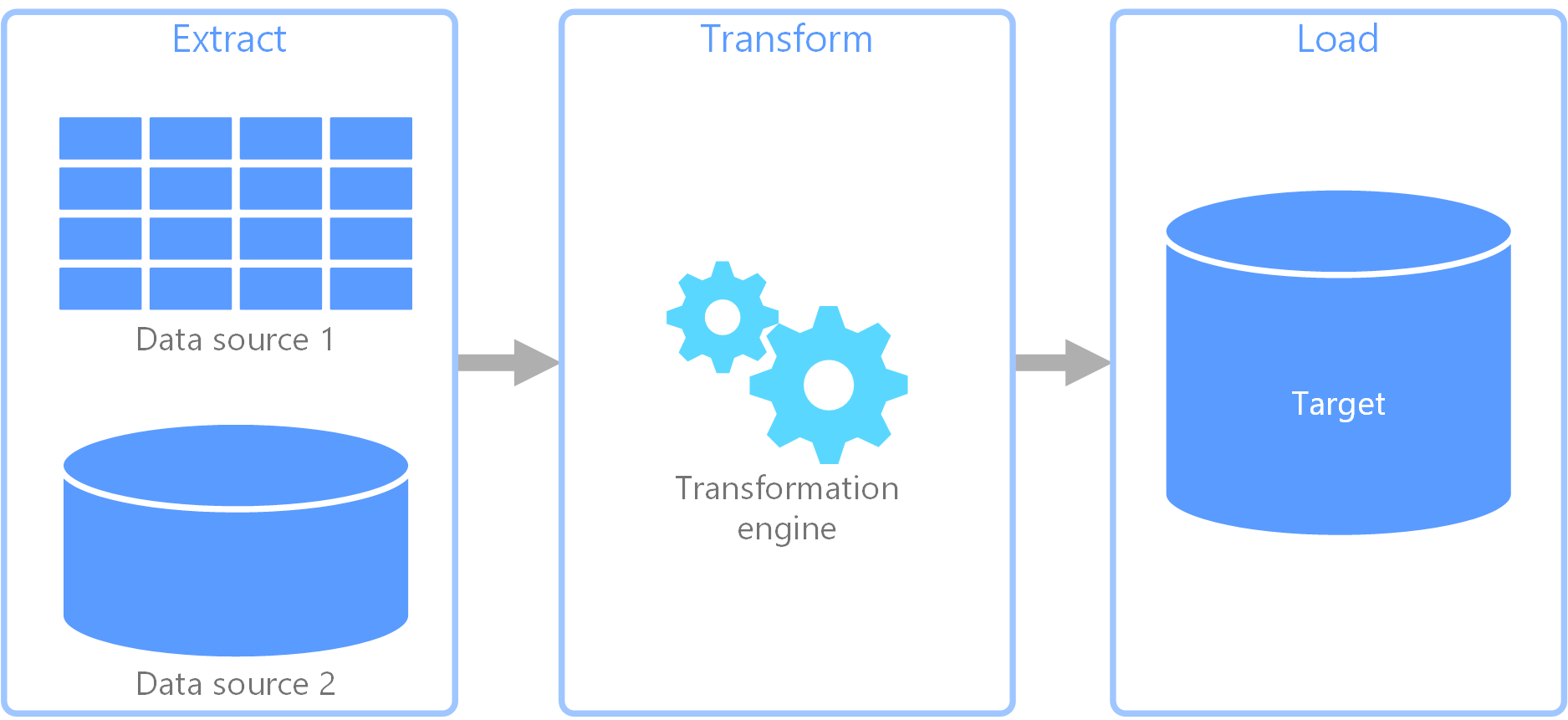
Integrating data from multiple sources into a single source (Data Ingestion)
Implementing Data Governance. Data governance is the process of managing and controlling data within a company (Data Quality, Data Security & Privacy, Data Access Management).
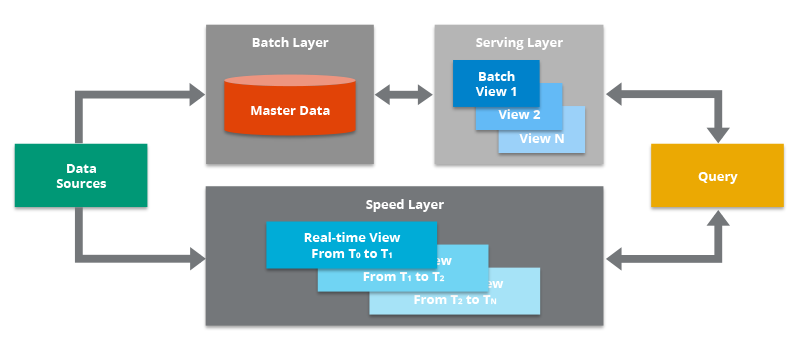
Data Lake focus is on storing raw and unstructured data from various sources in a storage location, in unstructured or semi-structured formats like files, images, or streaming data, at a low cost, and providing fast access to the data.
Data Warehouse focus is on creating a centralized storage location for data taken from various sources and organized in a way that can be used for analysis. Data in the data warehouse is transformed into a structured format and arranged in a star or snowflake schema, with the aim of supporting decision-making and business analysis.
Data marts are a subset of the data warehouse that focus on a specific business area, such as sales or finance. They are taken from the data warehouse and presented in a format suitable for business purposes. Data marts are used to meet the specific needs of departments or for specific business analysis needs.
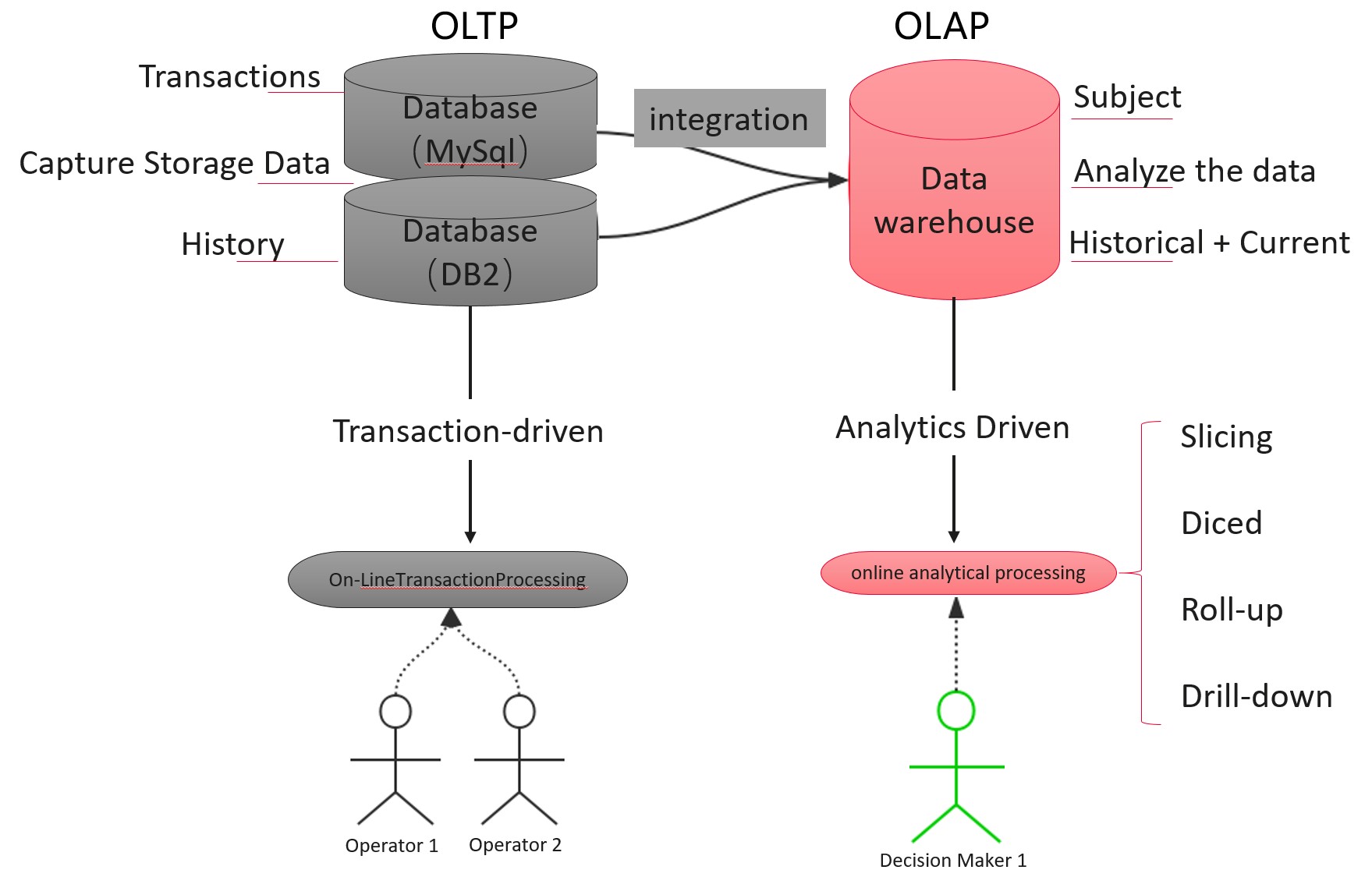
Relational databases consist of tables with rows and columns, which are related to each other using primary and foreign keys. The data is organized using a schema, and SQL (Structured Query Language) is used to interact with the database. Relational databases are suitable for applications that require high data integrity and complex transactions, and tools like MySQL, MS SQL Server, and PostgreSQL are commonly used.
Non-relational databases, also known as NoSQL, use a more flexible data model, such as document, graph, or key-value store, and are not organized in a fixed schema. They are suitable for applications that require horizontal scalability and the ability to manage unstructured data. Tools like MongoDB, Cassandra, and Redis are commonly used for NoSQL databases.