What is Big Data?
In the digital age, every click, transaction, sensor reading, and social media post generates data. Big Data refers to datasets whose size, complexity, and rate of growth make them extremely difficult to capture, manage, process, or analyze using traditional relational database management systems. It is not just about the massive amount of information; it is about the entire ecosystem required to extract meaningful insights from a chaotic sea of unstructured and structured data.

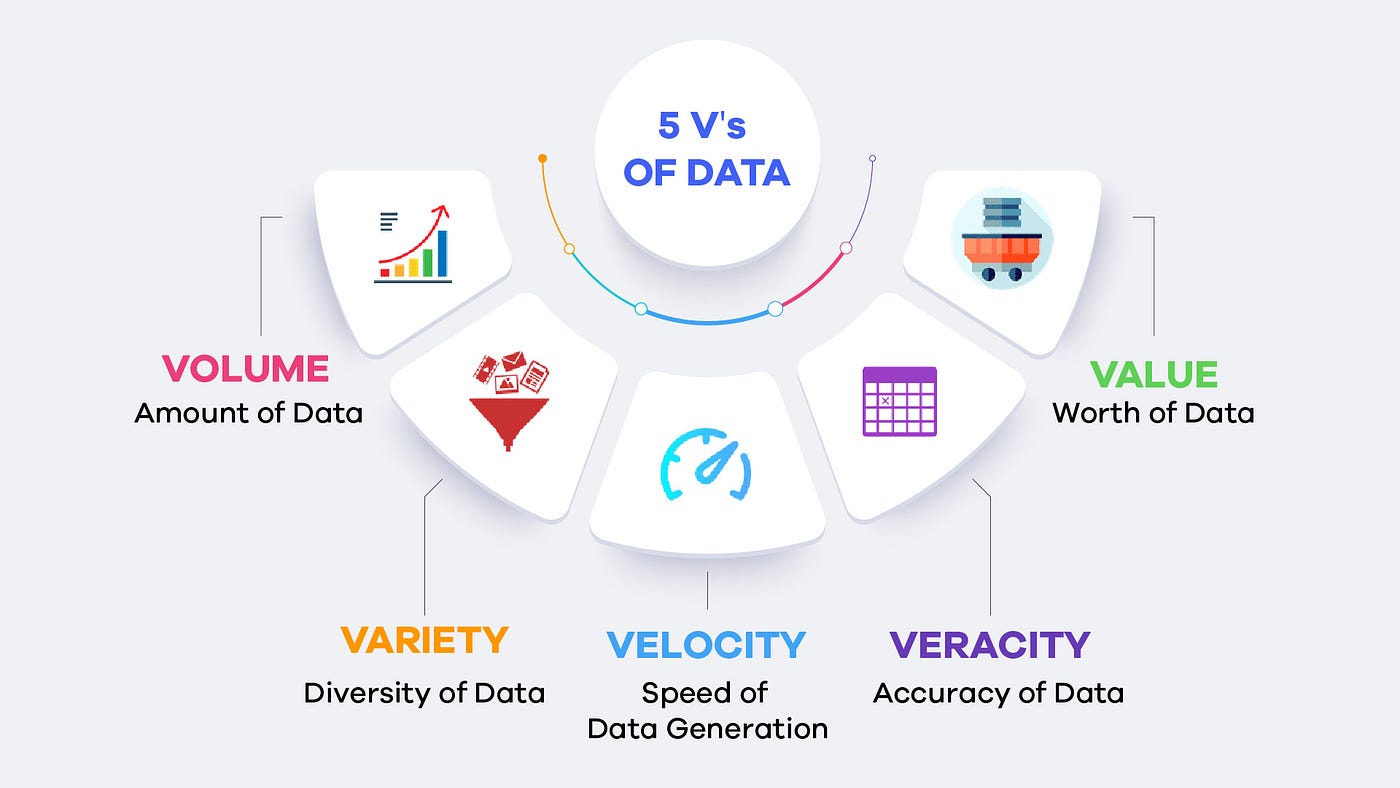
The 5Vs of Big Data
To truly understand the challenges and characteristics of Big Data, we rely on the framework known as the 5Vs:
- Volume: The sheer scale of data generated globally. We are no longer talking about Megabytes or Gigabytes, but rather Petabytes and Exabytes of information stored across vast data lakes.
- Velocity: The unprecedented speed at which new data is generated and moves. Think of real-time streaming data from IoT devices, financial trading algorithms, or social media feeds.
- Variety: The different types and formats of data. Modern data is highly heterogeneous, encompassing structured (SQL tables), semi-structured (JSON, XML), and entirely unstructured data (text, audio, video, images).
- Veracity: The accuracy, trustworthiness, and quality of the data. With so much data coming from diverse sources, ensuring it is clean, reliable, and free of bias is a monumental challenge.
- Value: The ultimate goal. Having massive amounts of fast-moving, varied data is completely useless unless you can extract actionable business value and strategic insights from it.
Why Hadoop for Big Data?
Before the modern Big Data era, scaling a database meant “scaling up” (buying a bigger, more expensive supercomputer). This approach quickly became financially and technically impossible. Apache Hadoop revolutionized the industry by introducing the concept of “scaling out.”
Instead of relying on one massive machine, Hadoop allows organizations to store and process huge amounts of data across clusters of cheap, commodity hardware. It is highly cost-effective, infinitely scalable, and inherently fault-tolerant—if one server in the cluster dies, the system automatically recovers and continues working without data loss.
What is Hadoop?
At its core, Apache Hadoop is an open-source software framework managed by the Apache Software Foundation. It is specifically designed for the distributed storage and processing of massive datasets. Rather than moving huge volumes of data to the software to be processed, Hadoop reverses the paradigm: it brings the processing software directly to where the data is stored.
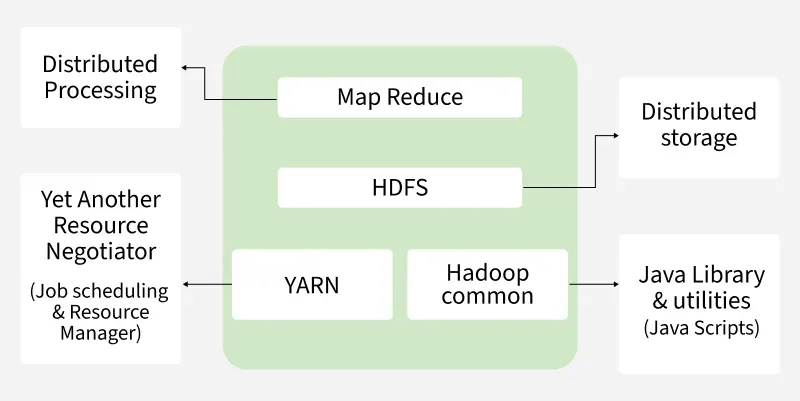
Hadoop Architecture in a Nutshell
The foundational architecture of Hadoop relies on three primary pillars:
- HDFS (Hadoop Distributed File System): The storage layer. HDFS takes massive files, chops them into smaller blocks (typically 128 MB), and distributes them across various nodes in the cluster, keeping multiple replicated copies for safety.
- YARN (Yet Another Resource Negotiator): The operating system of Hadoop. YARN manages the cluster’s computing resources (CPU, memory) and schedules the processing jobs, ensuring everything runs efficiently.
- MapReduce: The original processing engine. It splits a massive processing task into smaller, parallel sub-tasks (Map) and then aggregates the results back together (Reduce).
The Hadoop Ecosystem
Hadoop is rarely used alone; it is surrounded by a rich ecosystem of auxiliary tools that handle everything from data ingestion to machine learning:
- Processing: Apache Spark (for lightning-fast, in-memory processing).
- SQL/Querying: Apache Hive (for batch SQL) and Apache Impala (for real-time, interactive SQL queries).
- Data Ingestion: Apache Sqoop (for relational databases) and Apache Flume or Kafka (for streaming data).
- Coordination & Workflow: Apache ZooKeeper and Apache Oozie.

Essentially, How Hadoop Works: Distributed Storage & Parallel Processing
Imagine you need to count all the books in a massive library. Doing it alone (traditional computing) would take years. Hadoop’s approach is to hire 1,000 people (a cluster of nodes), assign each person one specific aisle (Distributed Storage), ask them to count their aisle simultaneously (Parallel Processing), and then have one manager tally up the 1,000 individual numbers to get the final result. By breaking data down into blocks and distributing the compute power, Hadoop processes petabytes of data in a fraction of the time.

The Evolution of Data Architecture: From Hadoop to the Lakehouse
While Hadoop laid the foundation for distributed computing, the data landscape has evolved rapidly to address its limitations. The journey of data architectures can be summarized in three major eras:
- The Data Warehouse Era: Before Hadoop, organizations relied entirely on traditional Data Warehouses. They were excellent for structured data and fast SQL queries but were rigid, incredibly expensive to scale, and completely incapable of handling unstructured data (like images or text logs).
- The Data Lake Era (Driven by Hadoop): To solve the storage cost and unstructured data problem, the Data Lake was born. Companies dumped massive amounts of raw, structured, and unstructured data into cheap storage layers (like HDFS or AWS S3). However, without proper governance, Data Lakes often turned into messy “Data Swamps.” Query performance was slow, and ensuring data quality was a nightmare.
- The Data Lakehouse Era (The Current Standard): Today, modern data engineering utilizes the Data Lakehouse. This architecture combines the best of both worlds: the cheap, scalable, and flexible storage of a Data Lake, alongside the strict governance, ACID transactions, and high-performance SQL capabilities of a Data Warehouse. Powered by open table formats like Apache Iceberg, Delta Lake, and Apache Hudi, the Lakehouse allows engines like Apache Spark and Impala to seamlessly query massive datasets with incredible efficiency.
Data is the New Oil
You have likely heard the famous quote: “Data is the new oil.” Just like crude oil, raw data is immensely valuable, but if unrefined, it cannot really be used. It has to be changed into gas, plastic, or chemicals to create a profitable entity. Similarly, data must be gathered, cleaned, structurally transformed, and analyzed for it to have any real value. The infrastructure (like the Lakehouse) is the oil rig, and Data Science is the refinery.
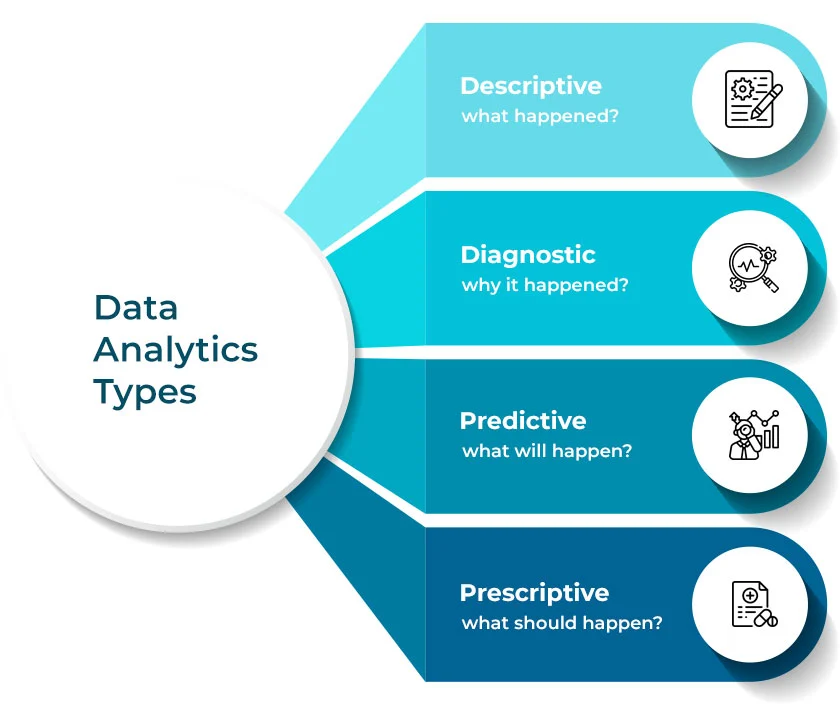
Analytics Approaches
Once the data is refined, organizations apply different levels of analytics to answer specific business questions:
- Descriptive Analytics: What happened? (e.g., Generating standard monthly sales reports).
- Diagnostic Analytics: Why did it happen? (e.g., Investigating why sales dropped specifically in one region last quarter).
- Predictive Analytics: What will happen? (e.g., Using machine learning to forecast next month’s demand based on historical trends).
- Prescriptive Analytics: What should we do? (e.g., Optimization algorithms suggesting the exact price adjustments needed to maximize profit).
- Cognitive Analytics: Systems that simulate human thought processes, continuously learning from new data to adapt their recommendations automatically.
The Data Science Hierarchy of Needs
A common mistake companies make is trying to build Artificial Intelligence before they have a solid foundation. Monica Rogati’s Data Science Hierarchy of Needs perfectly illustrates that you cannot do Deep Learning without first mastering data collection and engineering.

- Collect: Instrumentation, logging, sensors, and external data gathering.
- Move/Store: Reliable data flow, infrastructure, pipelines, ETL, and structured storage.
- Explore/Transform: Cleaning, anomaly detection, and preparing data for analysis.
- Aggregate/Label: Analytics, metrics, segments, aggregate features, and training data.
- Learn/Optimize: A/B testing, experimentation, and basic Machine Learning algorithms.
- AI / Deep Learning: The peak of the pyramid, requiring all the underlying layers to function correctly.
Data Analytics Terminologies
To navigate this field, it is crucial to understand the overlapping terminologies:
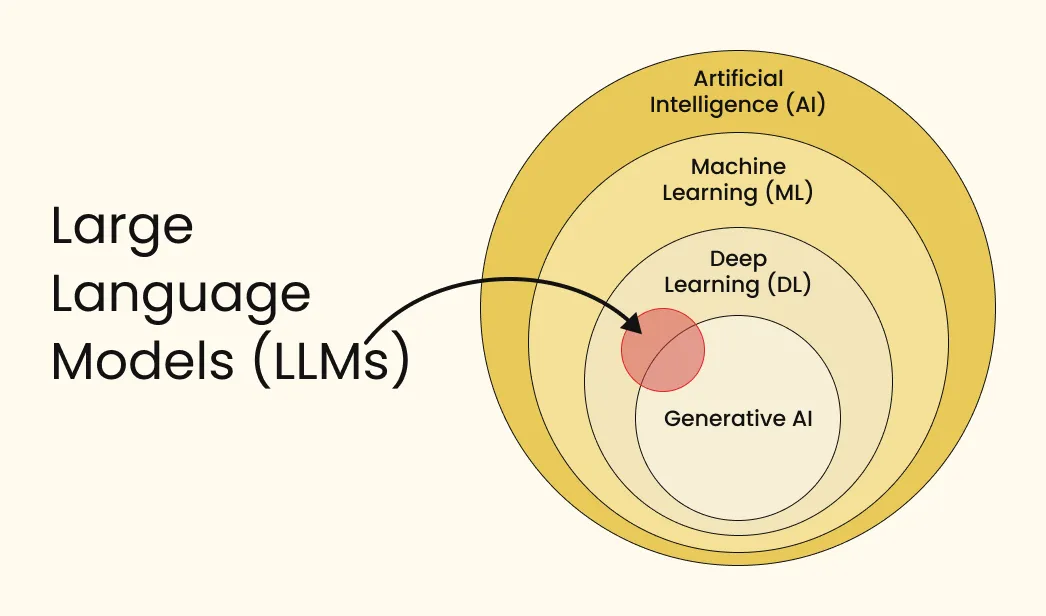
- Artificial Intelligence (AI): The broadest concept. Any technique that enables computers to mimic human intelligence, using logic, if-then rules, or complex models.
- Machine Learning (ML): A subset of AI that uses statistical methods to enable machines to improve at tasks with experience (data) without being explicitly programmed.
- Deep Learning (DL): A specialized subset of Machine Learning composed of algorithms that permit software to train itself to perform tasks by exposing multi-layered artificial neural networks to vast amounts of data.
- Data Science: An interdisciplinary field that uses scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data.
Brief History of AI, Machine Learning, Deep Learning, & LLM
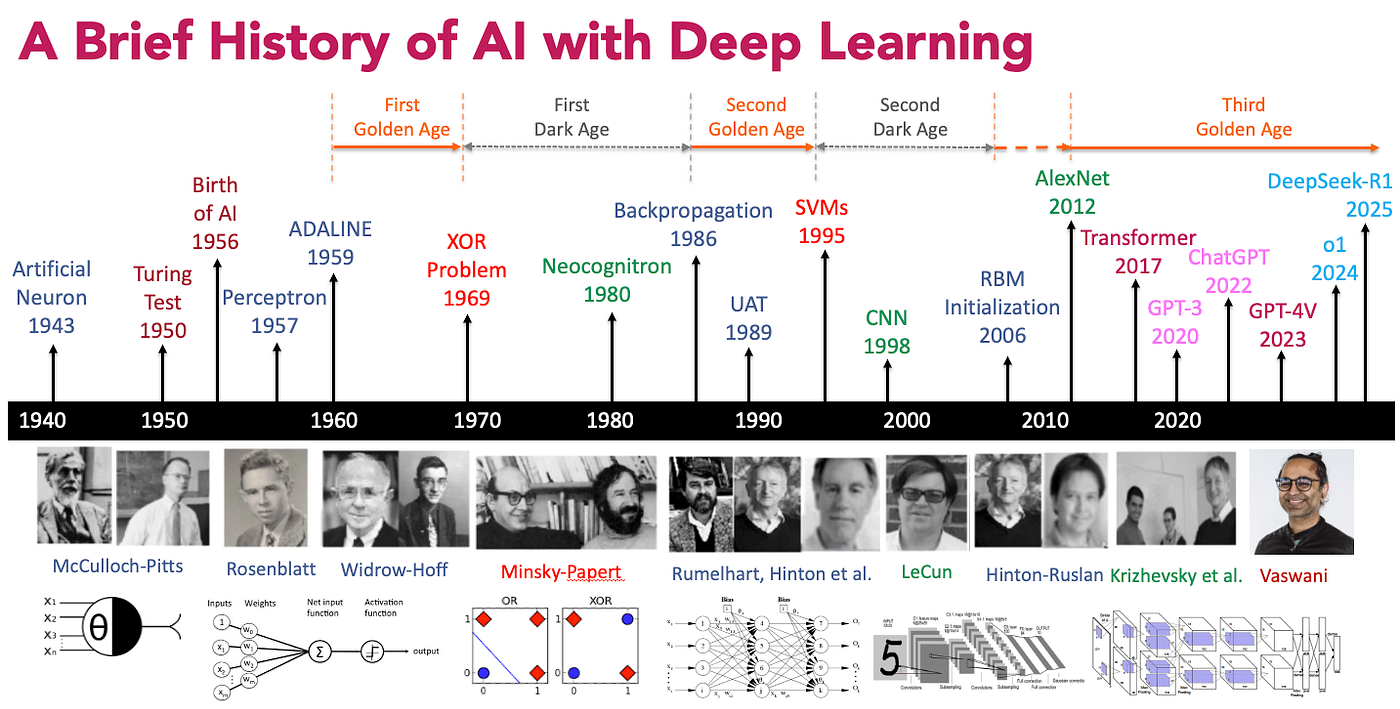
The journey to modern AI has been decades in the making:
- 1950s - The Dawn of AI: Alan Turing proposes the “Turing Test,” and the term “Artificial Intelligence” is officially coined at the Dartmouth Conference (1956). Early AI relied heavily on basic logic and symbolic reasoning.
- 1980s to 1990s - The Rise of Machine Learning: The focus shifts from hard-coded logic rules to algorithms that can learn from data. Spam filters and early recommendation systems are born.
- 2010s - The Deep Learning Boom: Thanks to the explosion of Big Data and the massive parallel processing power of GPUs, Deep Learning neural networks finally become viable, revolutionizing image recognition and natural language processing.
- Early 2020s - The Era of LLMs and Generative AI: The introduction of Transformer architectures leads to Large Language Models (LLMs). AI transitions from merely analyzing data to generating entirely new, human-like text, images, and code.
The Current State of Data Analytics and AI (2026 and Beyond)
Today, we have moved past the initial novelty of Generative AI chatbots. The modern data and AI landscape is defined by operational maturity and enterprise-scale deployment:
- From Generative to Agentic AI: We are no longer just prompting models for text generation. The frontier is now Agentic AI—autonomous systems capable of reasoning, breaking down complex goals, utilizing external tools, and executing multi-step workflows without constant human intervention.
- Multimodal Intelligence: Modern models natively process and reason across text, audio, images, and video simultaneously, bridging the gap between digital data and the physical world.
- Enterprise MLOps and Local Models: Organizations are shifting their focus heavily toward robust Machine Learning Operations (MLOps). Instead of relying solely on massive, external API-based models, enterprises are fine-tuning and deploying smaller, highly efficient open-source models locally within their own secure environments (like Cloudera Machine Learning) to guarantee data privacy and reduce latency.
- The Lakehouse Foundation: Ultimately, none of this advanced AI is possible without the architectural foundations discussed earlier. The success of modern AI models relies entirely on the continuous, clean, and governed flow of data provided by a robust Data Lakehouse.